Map Reduce concepts in Apache Spark, ML models and Java
All you need is Data Parallelism
The M/R pattern has a big influence in processing of data streams. What exactly is it?
Processing of large data streams requires large processing power with parallelism, to reduce processing-time. Since vertical scalability hits a wall with limits in physics, we need to go for node clusters for more processing power. That brings in the issues of data distribution among the nodes and ensuring that nodes can operate independently at full speed. The goal of Map-Reduce pattern is to allow maximum parallelism for data-processing workers. The pattern touches on the following 3 areas:
- Datasets
- Process-parallelism using CPU cores and node clusters
- Streaming of collections and data
Transformations and reductions
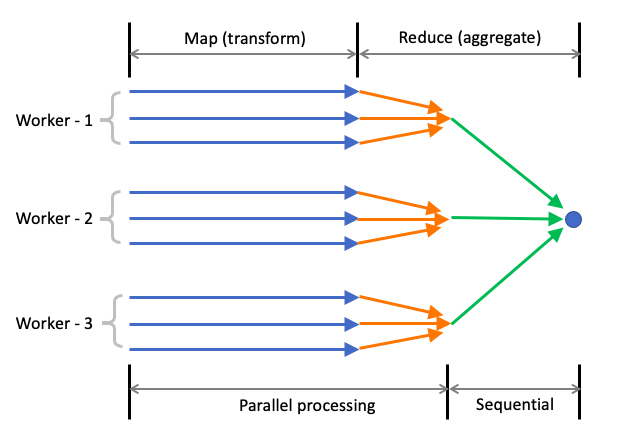
Map operation produces a dataset from an input dataset, while an aggregate or reduce operation produces a value from a dataset. And filter operation does something in-between - it produces a subset of the input dataset. Spark tranformations can be Map or Filter operations while Actions are reduce operations. Transformations are lazy - they are kicked off only when a downstream reduction operation is called.
A spark transformation is done across rows of data. Aggregate operations (groupby count etc) are relationships shared by multiple rows. So, map operations are unary transforms y = f(x), while reduce operations are aggredate operations y = f(X). Filter operations are row-subset operations.
Faster data I/O
Column databases allow faster aggregate queries, because the queries need a single column which is contiguos in storage. However, they are slow for single record-based queries such as find by pk or insert a new row. Row-based storage allows faster row operations while column storage allows faster aggregate queries.
Map Reduce in Machine Learning
ML frameworks such as Theano and Tensorflow create a graph of functions. The function graph runs only when a "reduce" operation is called. This could be a fit or evaluate operation.Another similarity is, the architecture of depp learning models reflect data processing pipelines. After all, the learning (tuning of weights) happens by pumping batches of data repeatedly through the pipeline or a function graph while adjusting the weights based on loss function gradient and back propagation of the loss.
The individual layers of a deep neural network (MLP) transform the input tensors. In case of Conv nets the transformation is defined by kernels or filters and in the case of RNNs, the transformation could result in creation of a context (or meaning). For a fully connected layer, the transformation is simply a matrix multiplication (and hence the need for GPU or TPU).
The raw incoming features go thorugh multiple transformation by kernels and finally reduced by a softmax or sigmoid in classification cases. That's a Map-Reduce in some form.
Map Reduce in Java
At a smaller scale, data parallelism and map-reduce are now built into programming lanugages as well. Java has fork-join API that supports a form of Map-Reduce.
Stream-processing in Java is another area where we can see Map-Reduce in action. The API support is pretty extensive and defines very neatly abut transforms, lazy operations and reductions.