Apache Spark through it's stack traces
One of my favorite ways of X-Ray'ing into a software is to look at the stacktrace to understand the call graph and its internal design. Stack-traces are beautiful. Let's have a look at a couple of these (Python and Scala) to learn some interesting stuff about Apache Spark.
Before jumping in, you might be wondering why I named a Scala code file with extension of .py in the sceenshots. Well - a quick story - Back in the 90's, when there was no good enough IDE for Java, I used to rename my .java files as .cpp and load them into Visual C++ IDE so that I get all the nice syntax highlighting and code editor features. I would use the jdk command-line to build and run my code. By the way, that was a single person project which was a phenomenal success (it recorded and replayed http sessions) and it launched me into the wonderful Java world (from C++).
The reason for using .py extension now in 2021 for the Scala code is similar. I wanted to use VSCode's jupyter extension (instead of browser-based notebook), but it won't recognize the code cells unless the file has a .py extension. However, the kernel can be changed to Scala interpreter giving me the compilation and run of the Scala code. So, That's the story. I'm borrowing the IDE features of an MS tool for my JVM-based code just as I did about 25 years back :)
Sorry for that ramble. Now, here is the first stack trace.
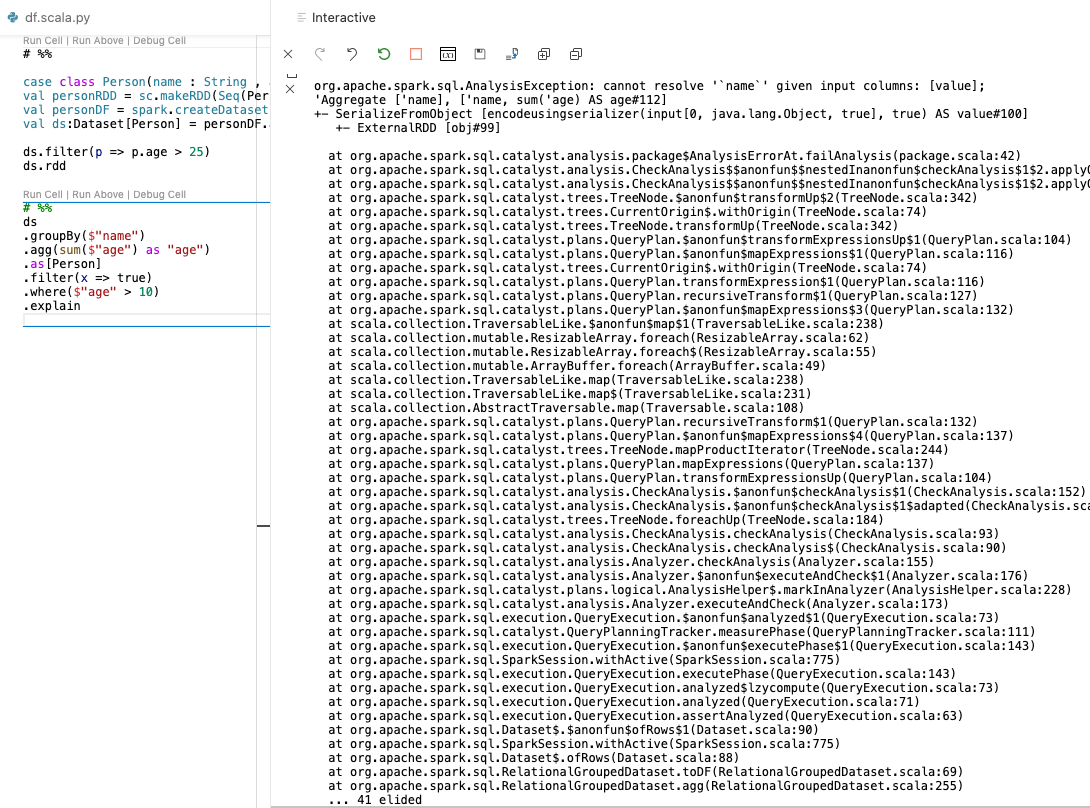
Stacktrace #1: Scala code - Analysis phase - Encoder issue
There are multiple phases when the Spark-Scala code is subjected to inspection. First, during compile time (checking for language-level errors), second, during Analysis phase (checking if the code makes sense from a query-plan perspective) and third, during run-time (crashing out if the compiled plan doesn't work with the data loaded).The one below is during the Analysis phase. You can see how the Catalyst engine proceeds to inspect the column types (because it is a Dataset, not RDD) and errors out when it sees a binary type column with default name "value", while code is expecting the correct column name. The actual problem here was the lack of an Encoder to deserialize the JVM object from the binary format.
Stacktrace #2: PySpark code - Run-time - JDBC Date parsing issue
This one is cleared through the analysis phase but errors out during run-time. So unlike the Analysis phase error, the story has three parts - P4J story, Driver story and the Worker story, because the code was running in these 3 different contexts after being launched through an action and encounters an issue.
Story from Jupyter/Py4J
Nothing much to see here. It just reports that something went wrong with the Java layer.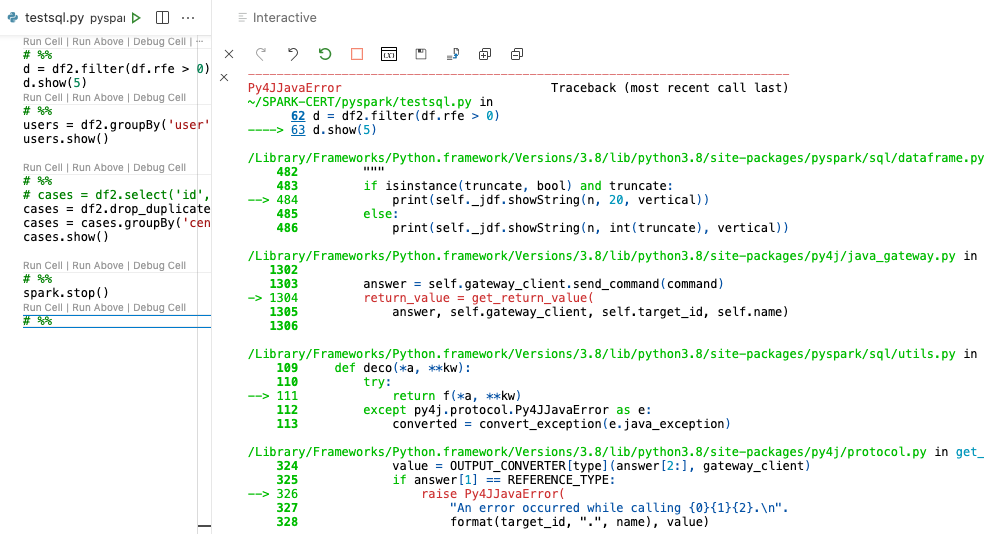
Story from the Cluster/Executor
To be fair, the Py4J layer also shows the error detail it has received, and the same is also reported in the Driver stacktrace as well. This worker-side story has a brief note: It received a task to read a JDBC record and it failed to do so.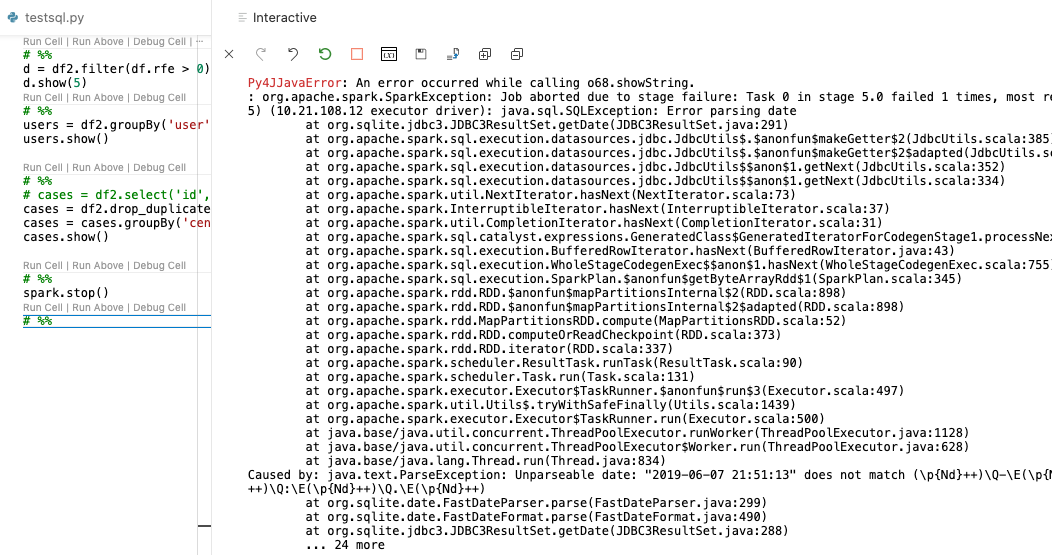
Story from the Spark Driver
This is a bit interesting. It shows the DAG scheduler running the graph of the stages in a job. It has a very nice trail of the story - receiving the job from the Gateway, starting at the action command (getRows()) and working backward through the query plan, and then the DAG Scheduler running in a separate process, receiving the job from the Driver etc.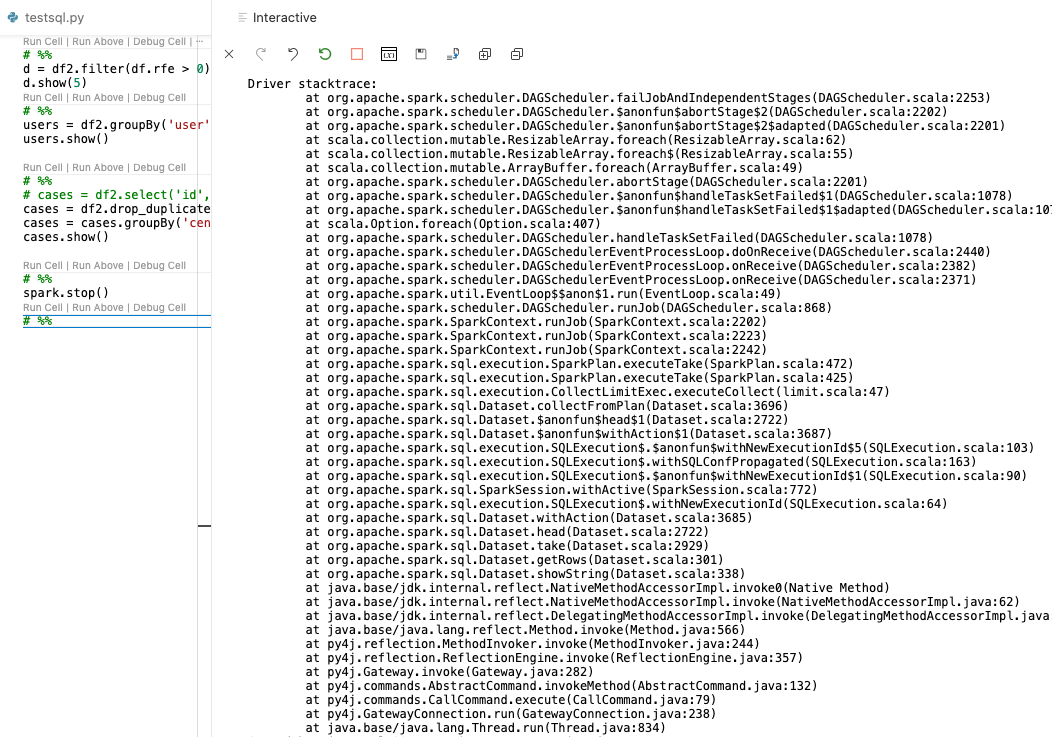
It is beautiful!